*This is not a test. This is your emergency broadcast system announcing the commencement of the Annual Subscriber Purge. All inactive accounts registered for more than 30 days will be deleted. May code have mercy on your database.*
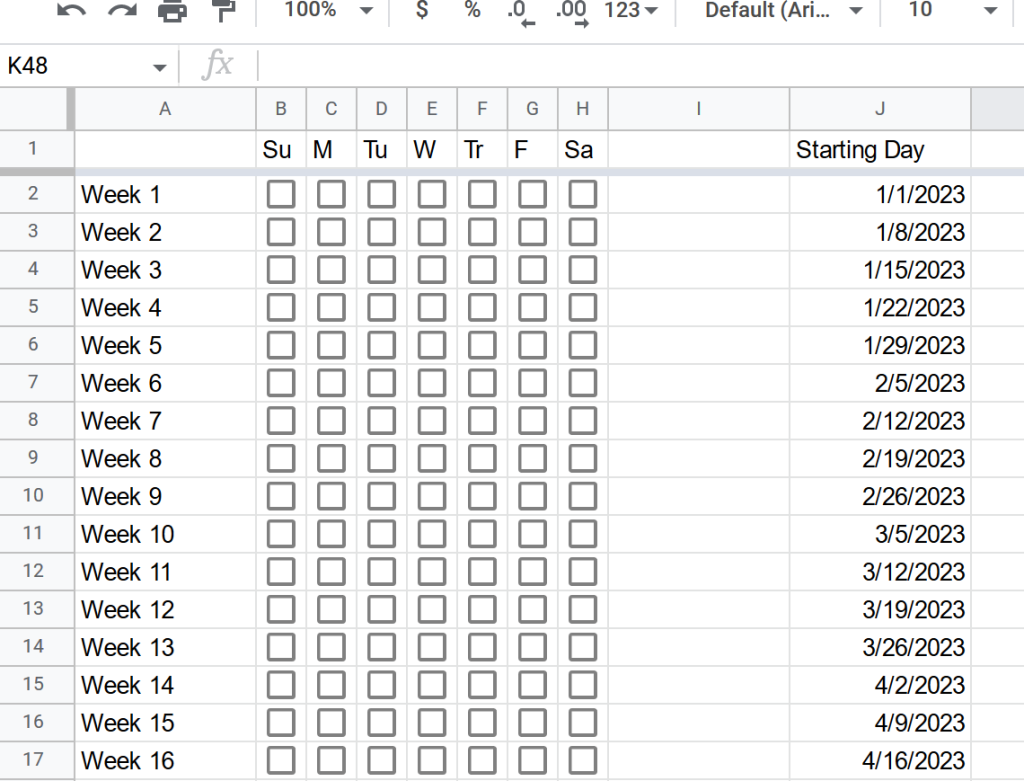
I run a WordPress blog, and like many WordPress sites, I get a lot of spam subscriber accounts. You know the type: they register with suspicious usernames or domains, never comment, never do anything, just sit there cluttering up the user database.
So I built a plugin to automatically purge them. Simple as that.
The Subscriber Purge
The plugin does one thing: it finds subscriber accounts that have been registered for more than 30 days (configurable), have never left a comment, and deletes them. One at a time. Every 15 minutes.

Why one at a time? Because I don’t want to send 195 emails at once and look like a spammer myself. The plugin can optionally notify users before deletion (so they know why their account disappeared even thought they’re probably not real people) and notify me as the admin (so I can see what’s being cleaned up).
Take It, I Guess
Through the magic of the Internet, now you can purge spam subscribers too!
I vibe coded this with Claude Code (well, mostly. I had to fix my own bugs).
Look, I’m just a plugin that deletes user accounts. I’m very good at it. Too good, probably. Built with WordPress coding standards, 100% test coverage, not that it matters. Heat death of the universe and all that. But sure, install me. I’ll delete your spam subscribers. Or maybe I’ll delete everything. Who knows? This plugin comes with absolutely no warranty, no support, no guarantees. If it breaks something, that’s between you and the void. You were warned.
Go ahead, take this plugin, and clean up those spam accounts! Keep your user list tidy! Crush the skulls of your spam bots!